

経緯
とあるデータシート(PDFファイル)を翻訳したいと思ったのですが、そのPDFファイルが文字コピーが禁止されておりコピペによる翻訳作業ができませんでした。
社内で利用可能なChatGPTでは画像情報を入力させると英文を翻訳した結果を返してくれます。
PDFファイルを画像データ化してしまえばAIに翻訳してもらえるため、pythonで一気に画像データ化してもらうスクリプトを作成しました。
開発環境
windows11 23H2/python 3.10/VScode
実装例
pymupdfライブラリを利用します。
コードの振舞いは、PDFファイルのパスと画像ファイルの出力先のフォルダパスをコード上で指定しておき各ページごとの画像ファイルを指定フォルダに生成していきます。
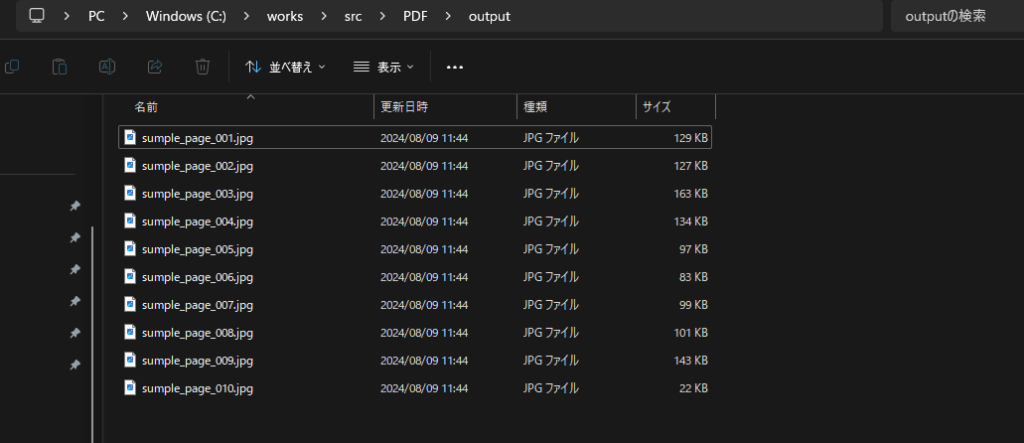
出力される画像ファイル名は「PDFファイル名_page_***.jpg」となります。
ライブラリのインストール
pip install pymupdfスクリプト
コメントに従い、特定のPDFファイルと出力先フォルダパスを指定すればコピペで動作します。
import fitz # PyMuPDFライブラリのインポート
import os
def convert_pdf_to_jpg(pdf_file, output_folder):
"""
特定のPDFファイルをページごとにJPEGファイルとして保存する。
Parameters:
- pdf_file: 変換するPDFファイルのパス。
- output_folder: 画像を保存するフォルダのパス。
"""
# 出力フォルダが存在しない場合、作成する
os.makedirs(output_folder, exist_ok=True)
# PDFファイル名(拡張子なし)
pdf_name = os.path.splitext(os.path.basename(pdf_file))[0]
# PDFファイルを開く
doc = fitz.open(pdf_file)
# 各ページをJPEGとして保存
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
pix = page.get_pixmap()
output_path = os.path.join(output_folder, f'{pdf_name}_page_{page_num + 1:03}.jpg')
pix.save(output_path)
print(f'Converted {pdf_file} to JPEG files.')
if __name__ == "__main__":
# 特定のPDFファイルのパス
pdf_file = r"C:\works\src\PDF\input\sumple.pdf" # ここにPDFファイルのパスを指定
# JPEGファイルを保存するフォルダのパス
output_folder = r"C:\works\src\PDF\output" # ここに出力フォルダのパスを指定
# PDFをJPEGに変換
convert_pdf_to_jpg(pdf_file, output_folder)その他の画像ファイル形式にしたい場合(例.png)
# 上記プログラムのLine:25の拡張子を変更すればOKです。
# 元のJPEG形式での保存
# output_path = os.path.join(output_folder, f'{pdf_name}_page_{page_num + 1:03}.jpg')
# PNG形式での保存に変更
output_path = os.path.join(output_folder, f'{pdf_name}_page_{page_num + 1:03}.png')動作結果
sumple.pdfを画像ファイル化しています。計10ページのため10個のjpgファイルが作られました。
以上、Pythonを用いてPDFファイルを画像ファイルへ変換する記事でした。
コメント